
The nbench-Byte benchmarks contain a set of well known algorithms to
exercise the CPU, on data sets typically fitting into the cache.
We run the standard tests that allow comparison with other systems (please see the data on the nbench
website), and a larger version of the Numeric Sort test that should
exercise the FSB because it uses non-sequential memory hits. The
results are in iterations per second.
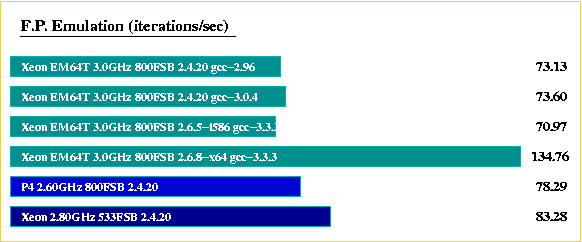
Standard NBENCH-BYTE (most tests fit into cache)








Large Numeric Sort in NBENCH-BYTE (545 MB RSS)

Observations
The 64-bit OS is generally up to two times faster for operations involving cache access, but can become up to two times slower when integers have to be moved to the memory, or when the FPU is involved intensively.
The 32-bit 2.6.5 kernel seems to have a performance problem with the byte-wide operation, compared to the the 64-bit 2.6.8 and the 2.4.20 kernels (unexpected).
The older Xeons and the P4 hardware is doing good if the data fits into the cache (as expected).
Here is the meaning of the tests as specified in the nbench documentation:
| Numeric sort | Generic integer performance. Should exercise non-sequential performance of cache (or memory if cache is less than 8K). Moves 32-bit longs at a time, so 16-bit processors will be at a disadvantage. |
| String sort | Tests memory-move performance. Should exercise non-sequential performance of cache, with added burden that moves are byte-wide and can occur on odd address boundaries. May tax the performance of cell-based processors that must perform additional shift operations to deal with bytes. |
| Bitfield | Exercises "bit twiddling" performance. Travels through memory in a somewhat sequential fashion; different from sorts in that data is merely altered in place. If properly compiled, takes into account 64-bit processors, which should see a boost. |
| Emulated F.P. | Past experience has shown this test to be a good measurement of overall performance. |
| Fourier | Good measure of transcendental and trigonometric performance of FPU. Little array activity, so this test should not be dependent of cache or memory architecture. |
| Assignment | The test moves through large integer arrays in both row-wise and column-wise fashion. Cache/memory with good sequential performance should see a boost (memory is altered in place -- no moving as in a sort operation). Processing is done in 32-bit chunks -- no advantage given to 64-bit processors. |
| Huffman | A combination of byte operations, bit twiddling, and overall integer manipulation. Should be a good general measurement. |
| IDEA | Moves through data sequenitally in 16-bit chunks. Should provide a good indication of raw speed. |
| Neural Net | Small-array floating-point test heavily dependent on the exponential function; less dependent on overall FPU performance. Small arrays, so cache/memory architecture should not come into play. |
| LU decomposition | A floating-point test that moves through arrays in both row-wise and column-wise fashion. Exercises only fundamental math operations (+, -, *, /) |